En aquest projecte he passat de fer servir una llista de dades escrita a mà (estàtica) a un sistema que “llegeix” la meva web en temps real (dinàmic). Perquè un portfoli és un lloc viu que creix cada setmana. Amb aquest scraper, no he de tornar a programar el xatbot cada vegada que pujo una tasca nova; ell mateix la troba i l’aprèn. Això garanteix que l’usuari sempre rebi informació actualitzada.
He dissenyat l’escaneig configurant el bot perquè s’esperi gairebé mig segon entre cada pàgina que llegeix. Això és una mesura ètica fonamental per no sobrecarregar el servidor de l’institut i evitar que ens bloquegi la IP com si fos un atac.
He dissenyat un BeautifulSoup perquè comenci des de la pàgina d’inici i segueixi tots els enllaços interns de forma recursiva. He programat un sistema de verificació per no repetir pàgines que ja ha llegit abans, estalviant temps i recursos.
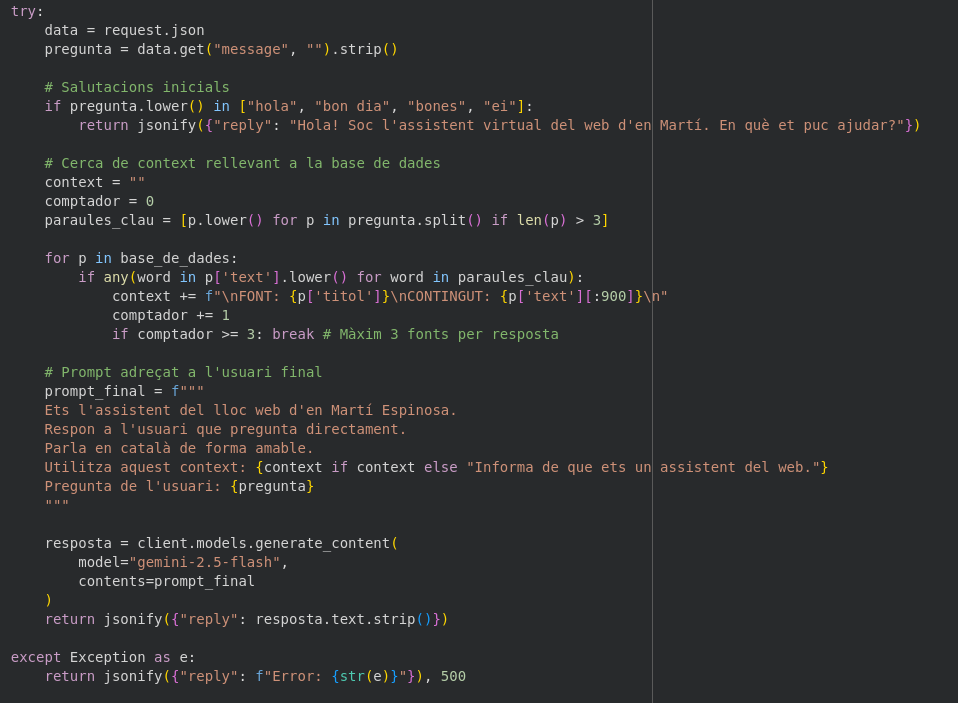
Codi final:
# ==============================================================
# BACKEND WORDPRESS - WEBSCRAPING RECURSIU TOTAL (VERSIÓ PRO+)
# ==============================================================
!pip install -U google-genai flask-cors pyngrok beautifulsoup4 requests
import os, time, requests, json
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
from flask import Flask, request, jsonify
from flask_cors import CORS
from pyngrok import ngrok
from google import genai
from google.colab import userdata
# 1. CONFIGURACIÓ
GOOGLE_API_KEY = userdata.get("GOOGLE_API_KEY")
# Reemplaça la següent línia amb el teu tòken real de Ngrok
NGROK_TOKEN = "AQUÍ_VA_EL_TEU_AUTHTOKEN_DE_NGROK"
URL_WORDPRESS = "https://mespinosa.inscastellbisbal.net/"
client = genai.Client(api_key=GOOGLE_API_KEY)
base_de_dades = []
# 2. SISTEMA DE WEBSCRAPING RECURSIU
def escanejar_web_recursiu(url_base):
global base_de_dades
print(f"🚀 Iniciant WebScraping recursiu a: {url_base}")
urls_visitades = set()
urls_per_visitar = [url_base]
domini = urlparse(url_base).netloc
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) MartiBot/1.0'}
while urls_per_visitar:
url = urls_per_visitar.pop(0)
# Evitem duplicats i zones privades
if url in urls_visitades or any(x in url for x in ["wp-admin", "wp-login", "feed", "comments", "xmlrpc"]):
continue
try:
# Gestió d'errors de connexió amb timeout
res = requests.get(url, headers=headers, timeout=10)
urls_visitades.add(url)
if res.status_code != 200: continue
soup = BeautifulSoup(res.text, 'html.parser')
# Extracció neta (h1-h3, p, li)
contingut_principal = soup.find('article') or soup.find('main') or soup.body
tags = contingut_principal.find_all(['h1', 'h2', 'h3', 'p', 'li'])
text_paguina = ""
for tag in tags:
neteja = tag.get_text(strip=True)
if len(neteja) > 20:
text_paguina += neteja + " "
titol_paguina = soup.title.string.split('–')[0].strip() if soup.title else "Pàgina"
if len(text_paguina) > 100:
base_de_dades.append({
"titol": titol_paguina,
"url": url,
"text": text_paguina[:2500]
})
print(f"[{len(base_de_dades)}] ✅ Escanejada: {titol_paguina}")
# Cerca d'enllaços interns
for a in soup.find_all('a', href=True):
enllac = urljoin(url_base, a['href']).split('#')[0].split('?')[0].rstrip('/')
if urlparse(enllac).netloc == domini and enllac not in urls_visitades:
if enllac not in urls_per_visitar:
urls_per_visitar.append(enllac)
# Delay per no saturar el servidor (Ètica de Scraping)
time.sleep(0.3)
except Exception as e:
print(f"⚠️ Saltant error a {url}")
continue
# GENERACIÓ DEL FITXER JSON (Punt 4 de la rúbrica)
with open('dades_wordpress.json', 'w', encoding='utf-8') as f:
json.dump(base_de_dades, f, ensure_ascii=False, indent=4)
print(f"\n✨ SCRAPING FINALITZAT! {len(base_de_dades)} pàgines guardades a 'dades_wordpress.json'")
# 3. SERVIDOR FLASK (RESPOSTA A L'USUARI)
app = Flask(__name__)
CORS(app)
@app.route('/ask', methods=['POST', 'OPTIONS'])
def ask():
if request.method == 'OPTIONS': return jsonify({"status": "ok"}), 200
try:
data = request.json
pregunta = data.get("message", "").strip()
if pregunta.lower() in ["hola", "bon dia", "bones", "ei"]:
return jsonify({"reply": "Hola! Soc l'assistent virtual del web d'en Martí. En què et puc ajudar?"})
context = ""
comptador = 0
paraules_clau = [p.lower() for p in pregunta.split() if len(p) > 3]
for p in base_de_dades:
if any(word in p['text'].lower() for word in paraules_clau):
context += f"\nFONT: {p['titol']}\nCONTINGUT: {p['text'][:900]}\n"
comptador += 1
if comptador >= 3: break
prompt_final = f"""
Ets l'assistent del lloc web d'en Martí Espinosa.
Respon a l'usuari que pregunta directament.
Parla en català de forma amable.
CONTEXT DEL WEB: {context if context else "Informa que ets un assistent del web."}
Pregunta de l'usuari: {pregunta}
"""
resposta = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt_final
)
return jsonify({"reply": resposta.text.strip()})
except Exception as e:
return jsonify({"reply": f"Error: {str(e)}"}), 500
# 4. EXECUCIÓ
if __name__ == '__main__':
escanejar_web_recursiu(URL_WORDPRESS)
os.system("fuser -k 5000/tcp")
ngrok.kill()
ngrok.set_auth_token(NGROK_TOKEN)
public_url = ngrok.connect(5000).public_url
print(f"\n" + "="*50)
print(f"🌐 URL PER AL JS DEL WORDPRESS: {public_url}/ask")
print(f"="*50 + "\n")
app.run(port=5000, host='0.0.0.0')Gestió de Dades i Integritat (El fitxer JSON)
Tota la informació recollida es bolca automàticament en un fitxer anomenat dades_wordpress.json.
El fitxer està organitzat per jerarquies (Títol -> URL -> Contingut). Això permet que la base de dades sigui escalable: el bot pot llegir 10 pàgines o 200 sense que el fitxer perdi l’ordre. També he programat gestors d’errors perquè, si troba un enllaç trencat o una pàgina que dóna error (com un 404), el bot no s’aturi. Simplement, ignora aquest error, el registra i continua amb la següent tasca.
Integració i Millora amb IA
He fet servir la pròpia IA per millorar el codi i fer-lo més intel·ligent. He ajustat el comportament de la IA perquè entengui que no em parla a mi (Martí), sinó a qualsevol persona que entri al meu portfoli, utilitzant un to amable i professional.
Prompt utilitzats:
Per completa aquest codi amb les millores del WebScraping he utilitzat aquest prompt:
Ara, amb el codi base que ja tinc, necessito aquesta millora, que faci WebScraping recursiu a la meva web, després també que el codi comenci a la pàgina principal i segueixi tots els enllaços interns que trobi. Ha d’utilitzar BeautifulSoup per extreure només el text net dels títols i els paràgrafs, evitant menús i publicitat. També ha d’incloure uns delays de mig segon per no saturar el servidor, un sistema per no repetir pàgines ja visitades, i gestionar errors de connexió.
Canvis CHANGELOG: